- find features,
- make computational graphs on features
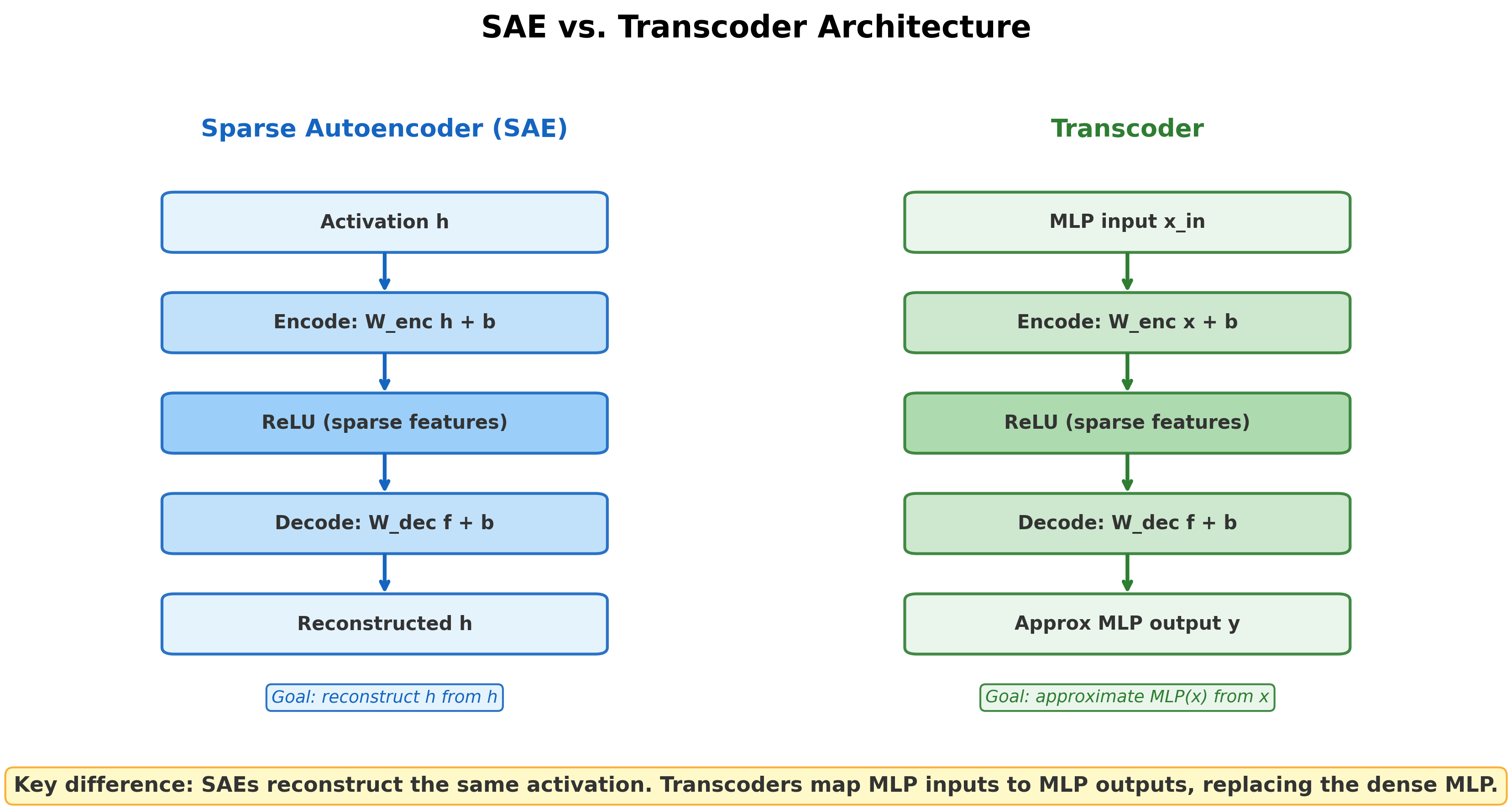
SAEs: try to reconstruct “h” the activations of MLP after running ReLU, u have the activations of the layer. u reconstruct it, using Auto encoder
transcoders: try to replace the MLP.
- it takes input
- W times x, then ReLU,
- the output “h”
the plan is to replace the MLP with a sparse autoencoder that takes “the input”(which MLP takes), and spit out “h”.
u are NOT reconstruction “h”, but rather replacing MLP
error adjustment for faithful replacement of MLP
Adds an error adjustment to the CLT output at each (token position, layer) pair equal to the difference between the true MLP output on pp and the CLT output on pp (
reference: https://arxiv.org/pdf/2403.19647 ?
The “Word → say _W” edges represent attention heads’ OV circuits writing to a subspace that is then amplified by MLPs at the target position.
OV writing to subspace , then amplified by MLP.
This subspace/Basis, is it all one basis? does each layer, has its own basis?
intervention also works:
- but here intervention is done like adding a steering vector
- one would expect,
- increase desired feature strength in high dim space
- decode the vector ( use it as MLP output)
- but they are using existing MLP output + decoded vector (kind of steering vector)