- Head 1 is redundant
- In Head 3, 2nd position attends a lot of the previous number if its > current number
- its not in direction, Like ANS vector aligning directionally
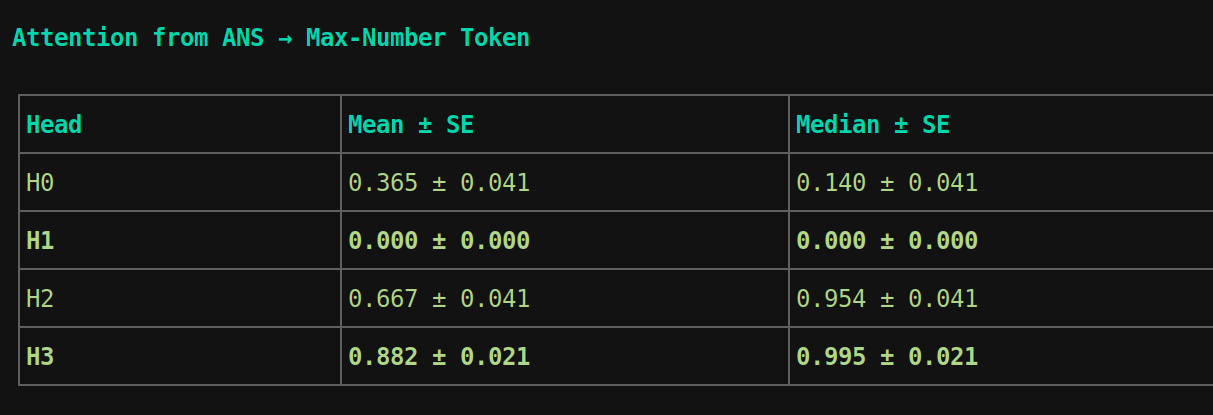
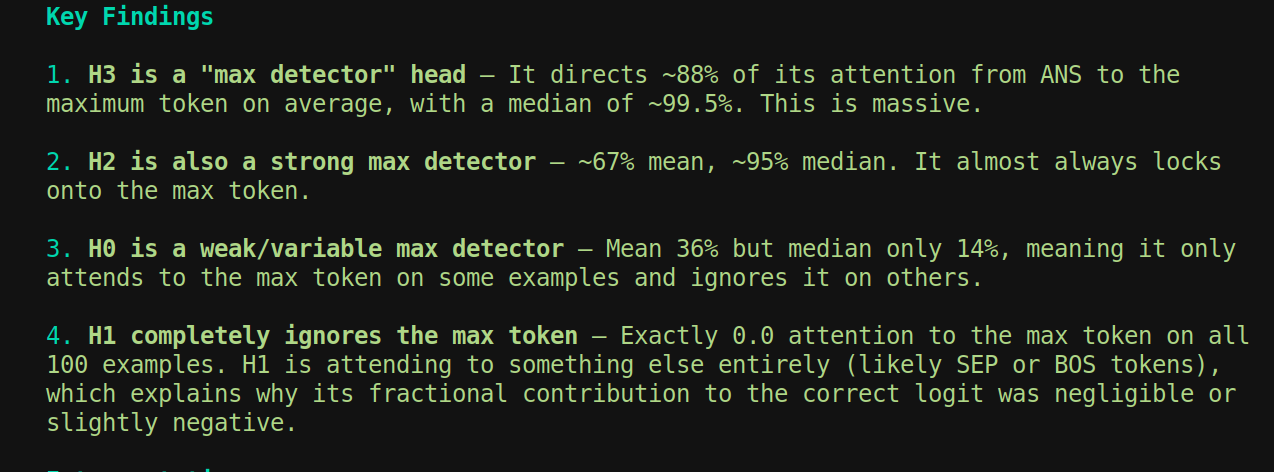
How much dooes ANS token attend to maximum number
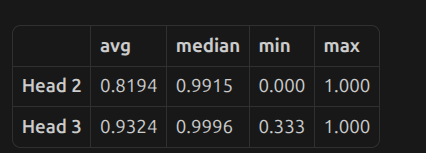
- At scale=0 (fully removed): big accuracy drops
- At scale=0.1 (just 10% of the original score retained): 100% accuracy is already restored
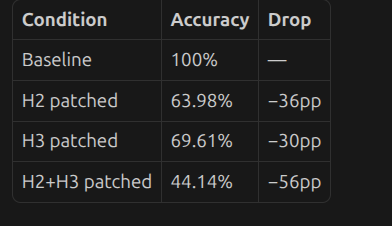
so ANS token attending to max number in head 2 and head 3 is not true Hard zero (scale=0) — above chance, not random:
-
H2 zeroed: 64% (chance is 10%) — the other heads compensate partially
-
H3 zeroed: 70%
-
Both zeroed: 44% — still well above chance, meaning Heads 0 and the residual stream carry some signal even without these attention edges
-
H2 fully recovers at scale=0.08 — needs just 8% of its original ANS→max score
-
H3 needs ~17% to fully recover — slightly more dependent on the magnitude
The norms are NOT monotonically ordered with value (0→9) — 6 is the biggest, 3 and 7 are tiny.
Invariance testing
its not about the position, its about the number (2,1,1,1,1)..(1,2,1,1,1) …(1,1,1,1,2) all have same answer From where do they start divering:
-
Not at final residual stream for sure
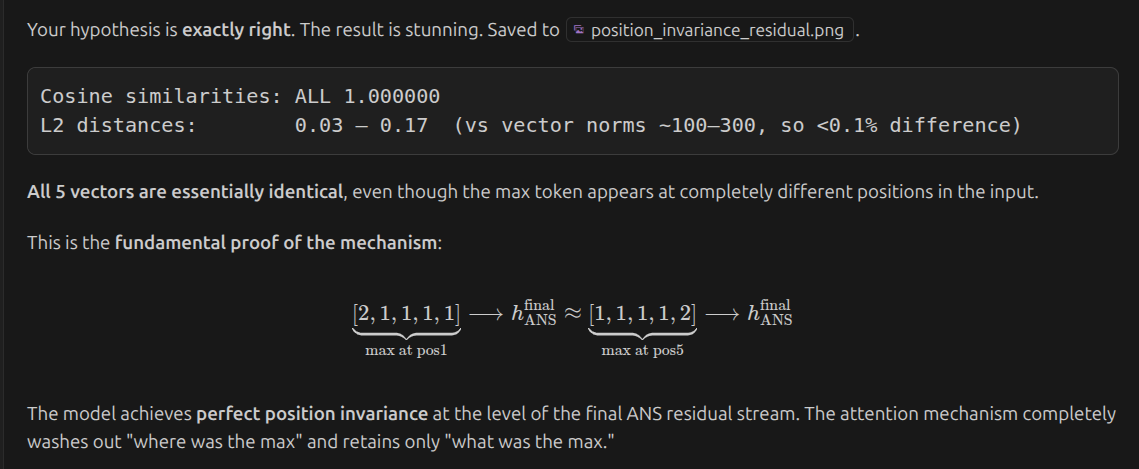
-
Now that we know initial residual stream’s final row is always same. and final is also same, then the thing added to residual stream should also be same
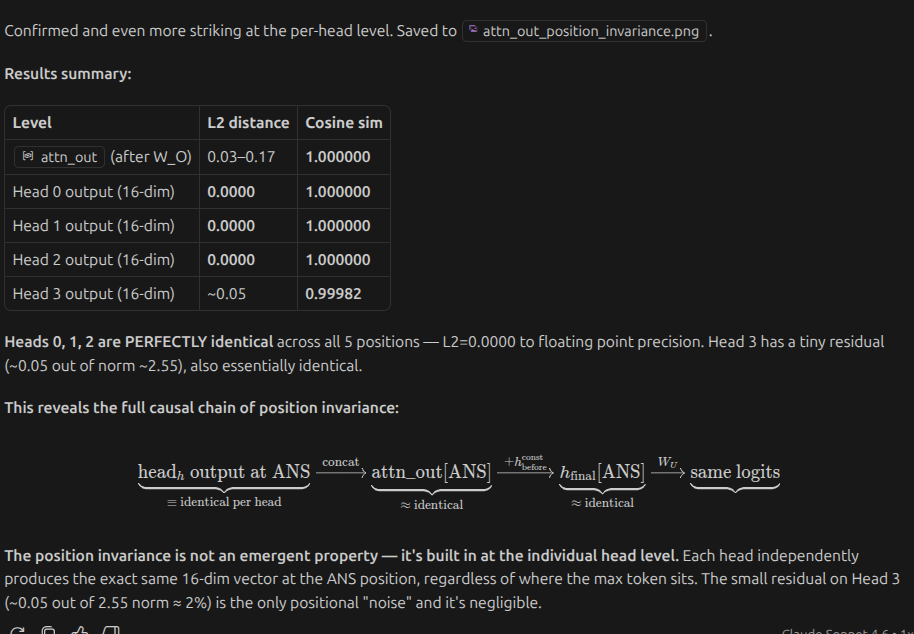
-
concatenation of 4 attention heads is also same?
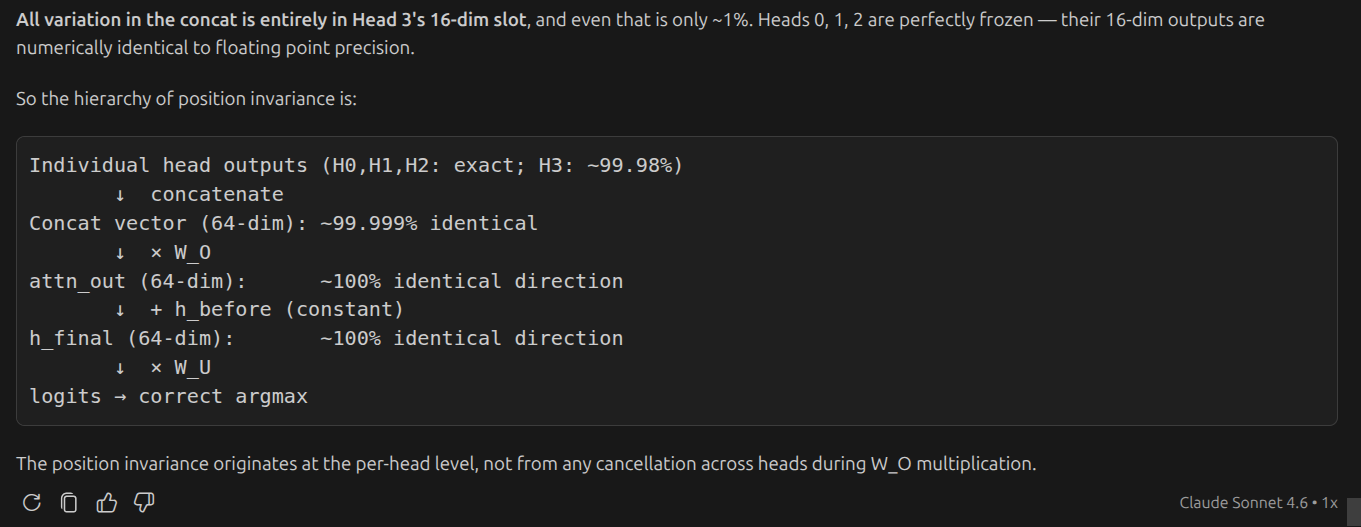
-
its surprising that even after changing position of the maximum number the entire concatentation is same. and also head outputs are same. the value matrix and attention must be doing some magic
so lets check attention matrix similarity in all 5 cases now, for each head
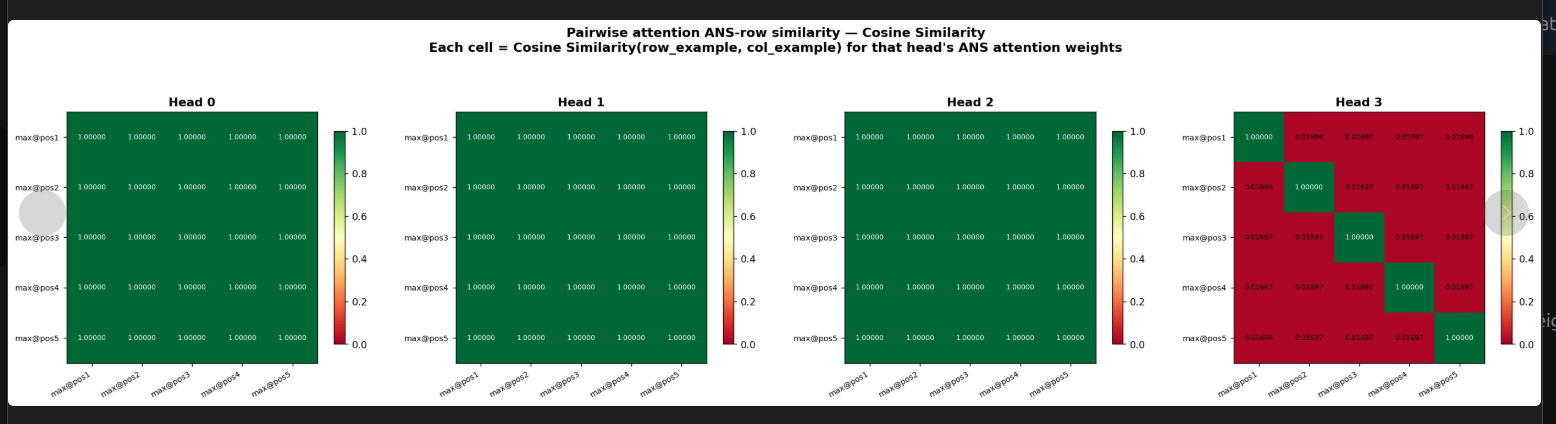
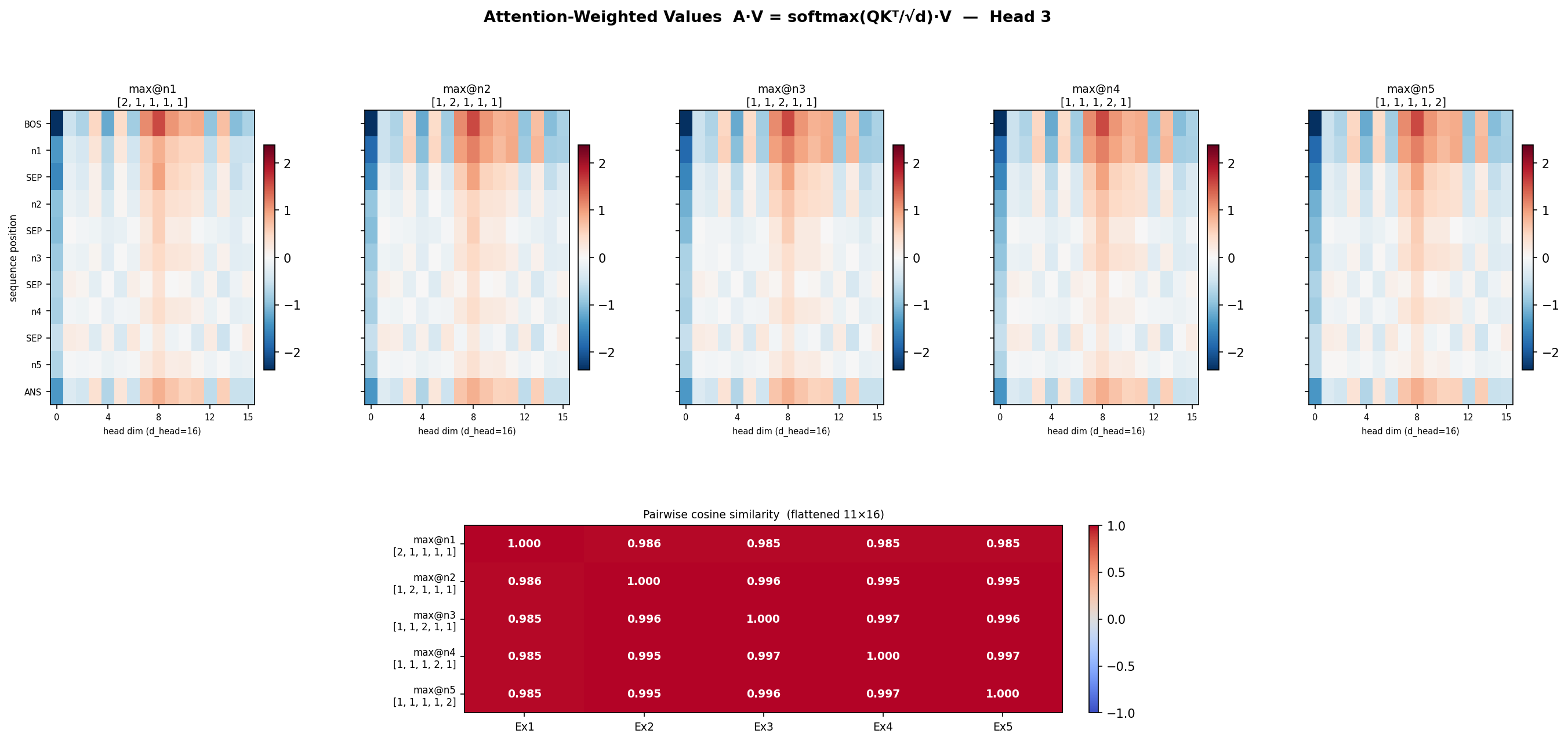
- so let’s shift our attention to attention head 3. attention matrices are different. but the values should be different also no? lets confirm? Head 3’s QK^T times V
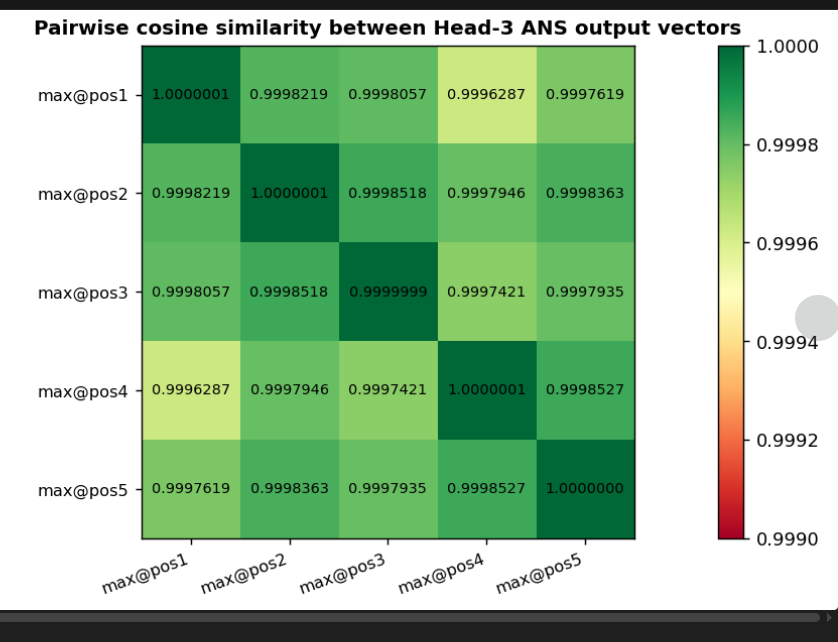
- its impressive that QK^T is different, but QK^T times V is same. But wait, we forgot to check value vector’s last row

So QK^T is different only for head 3. Value vector for last row is also same(because its final answer)
So basically V[ANS] is same, QK^T is different, but QK^T V[ANS] is same?, it should be different no? 1 x 16
-
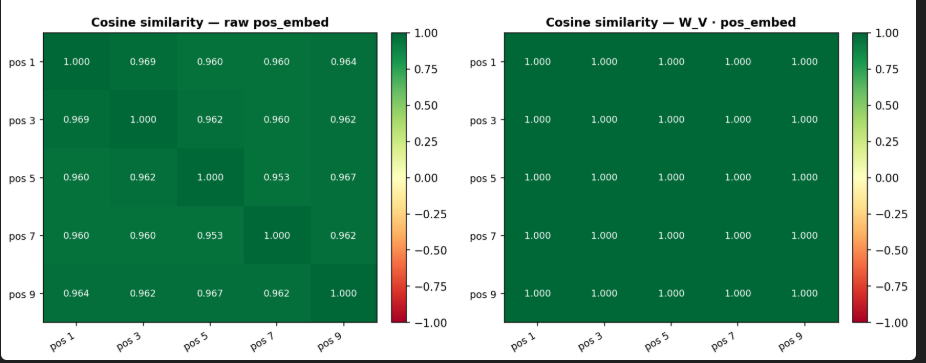
positional embeddings are already very similar, because position doesn’t matter in this problem
-
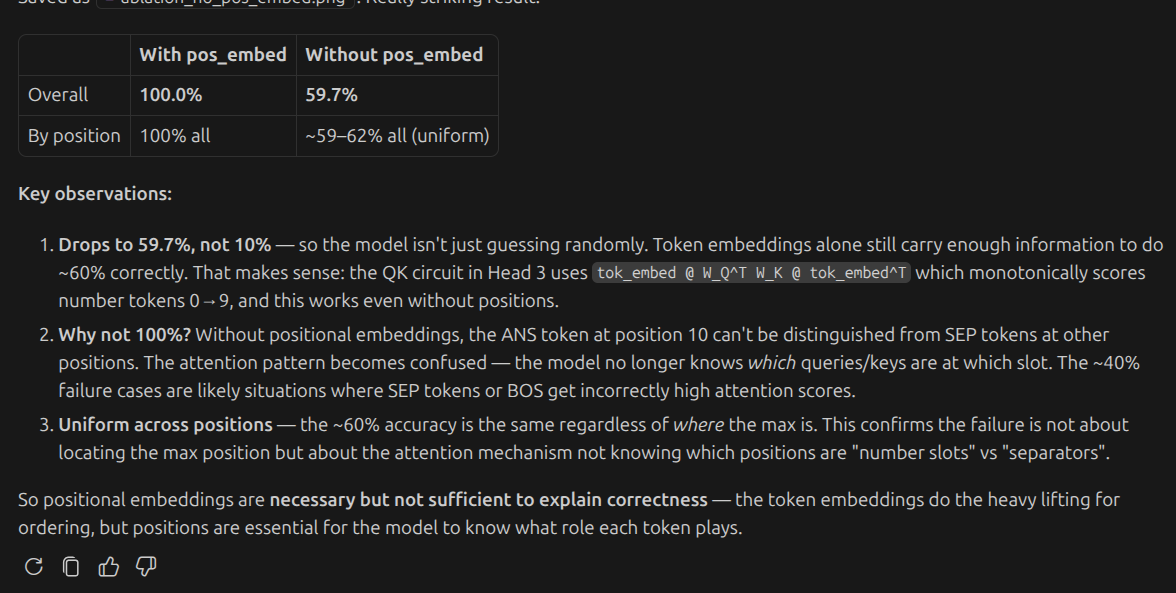
so positional embeddigs do matter
-
all positions do matter
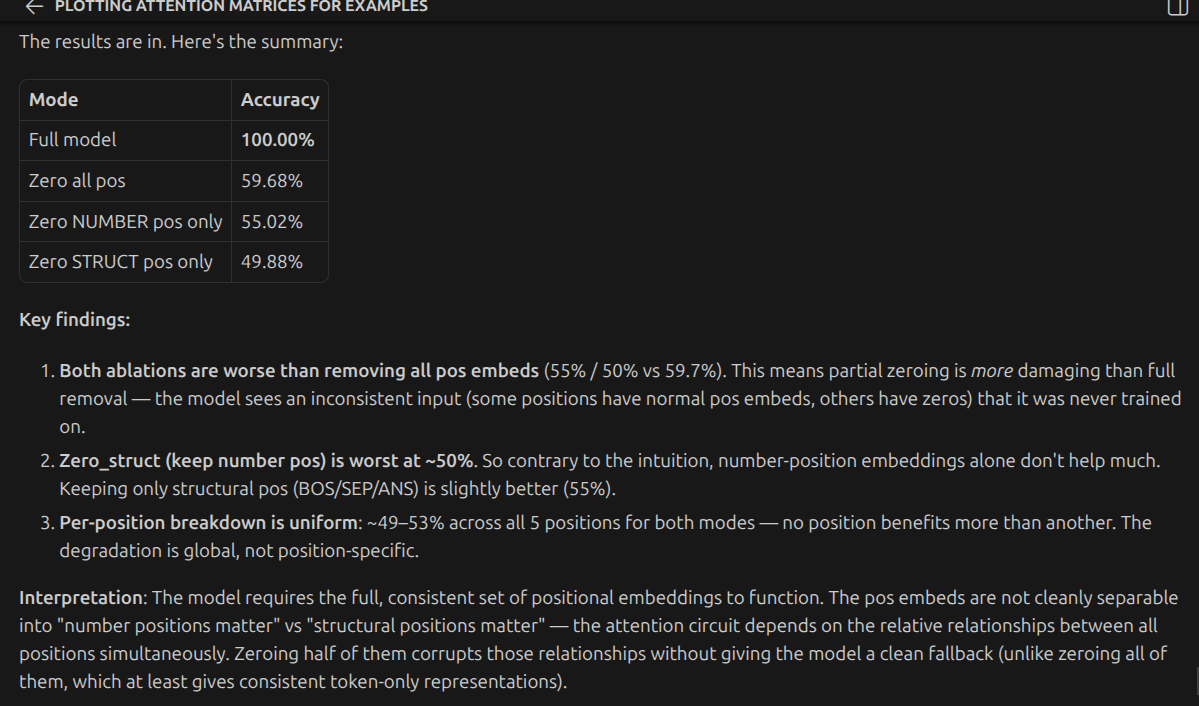
Check stage by stage invariance
Initial Residual stream
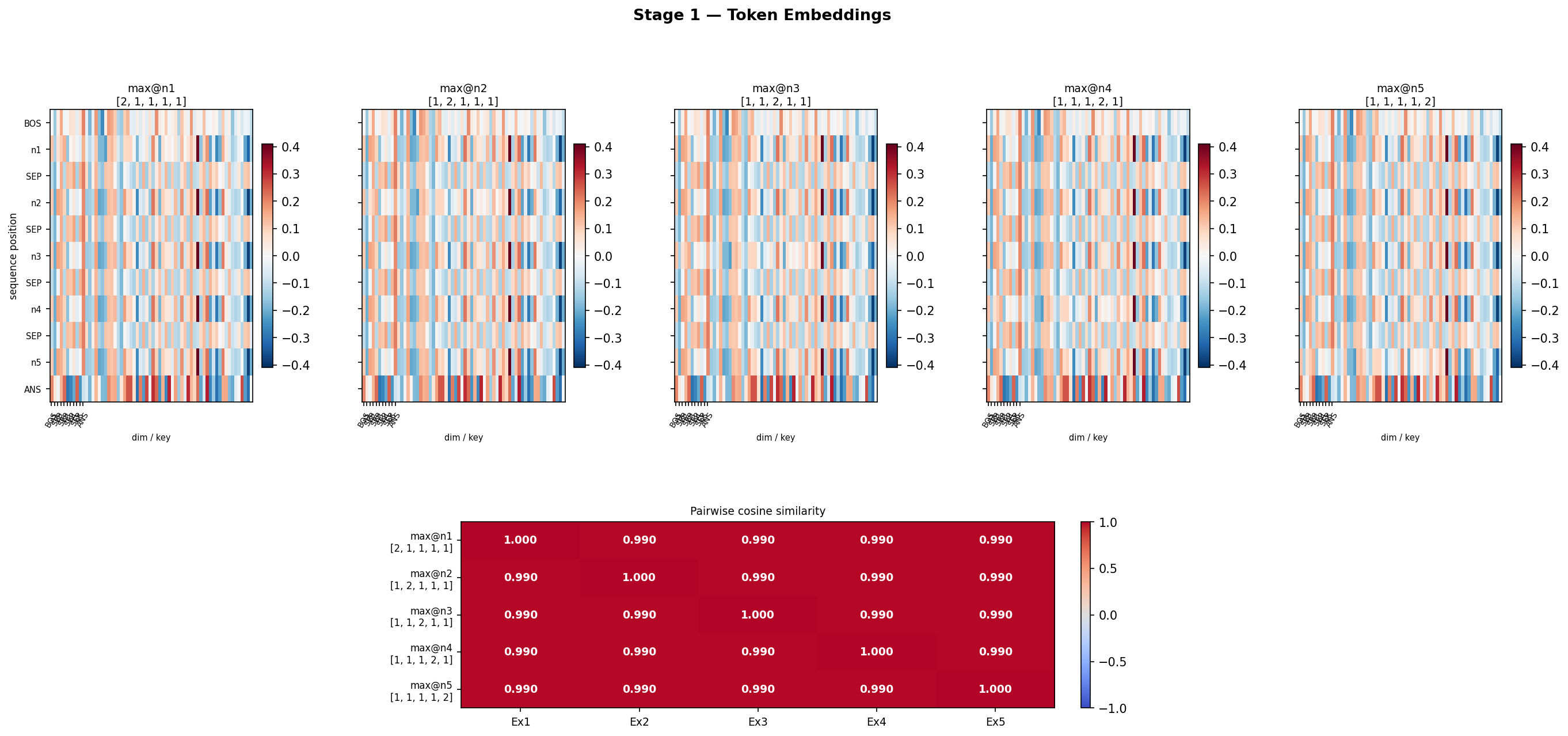
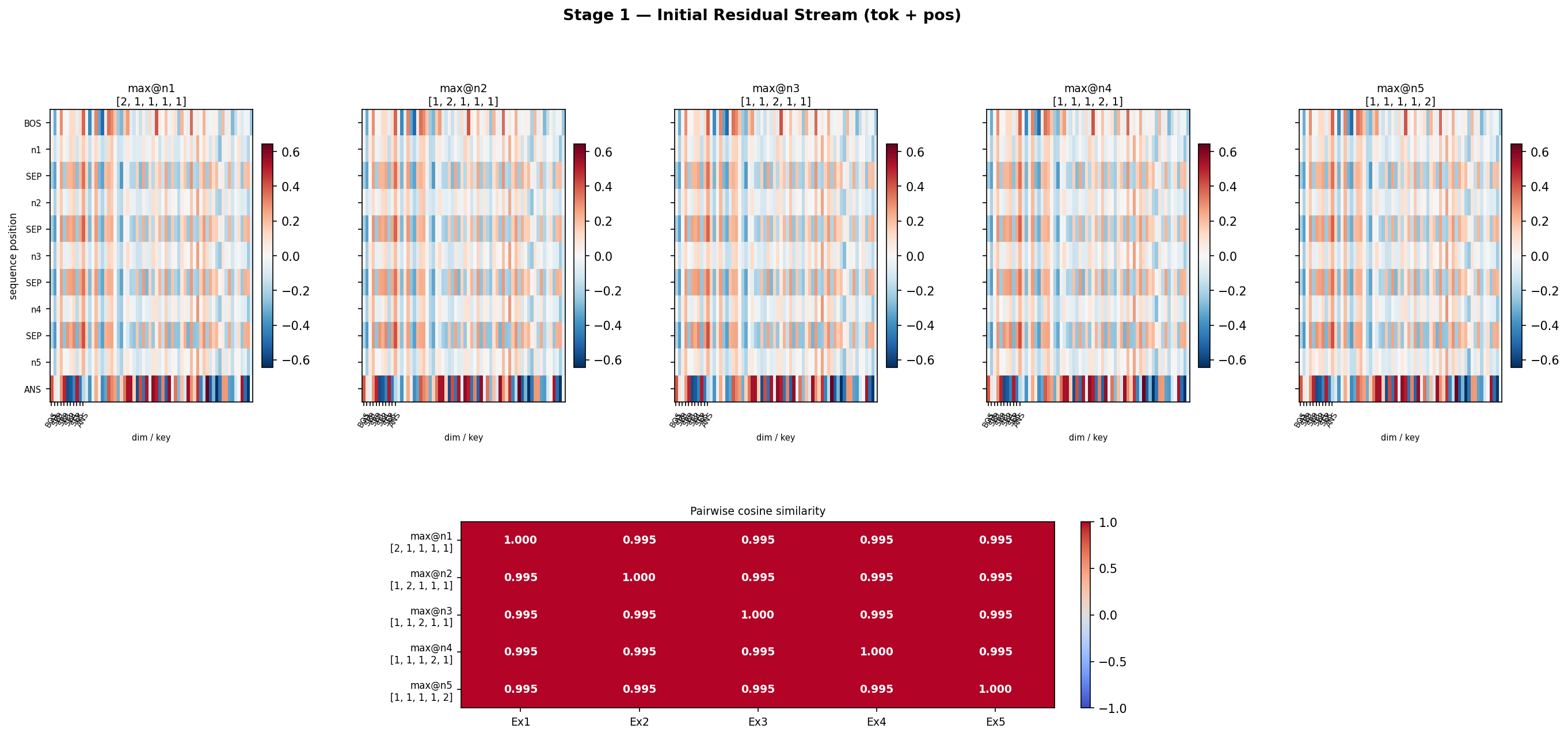
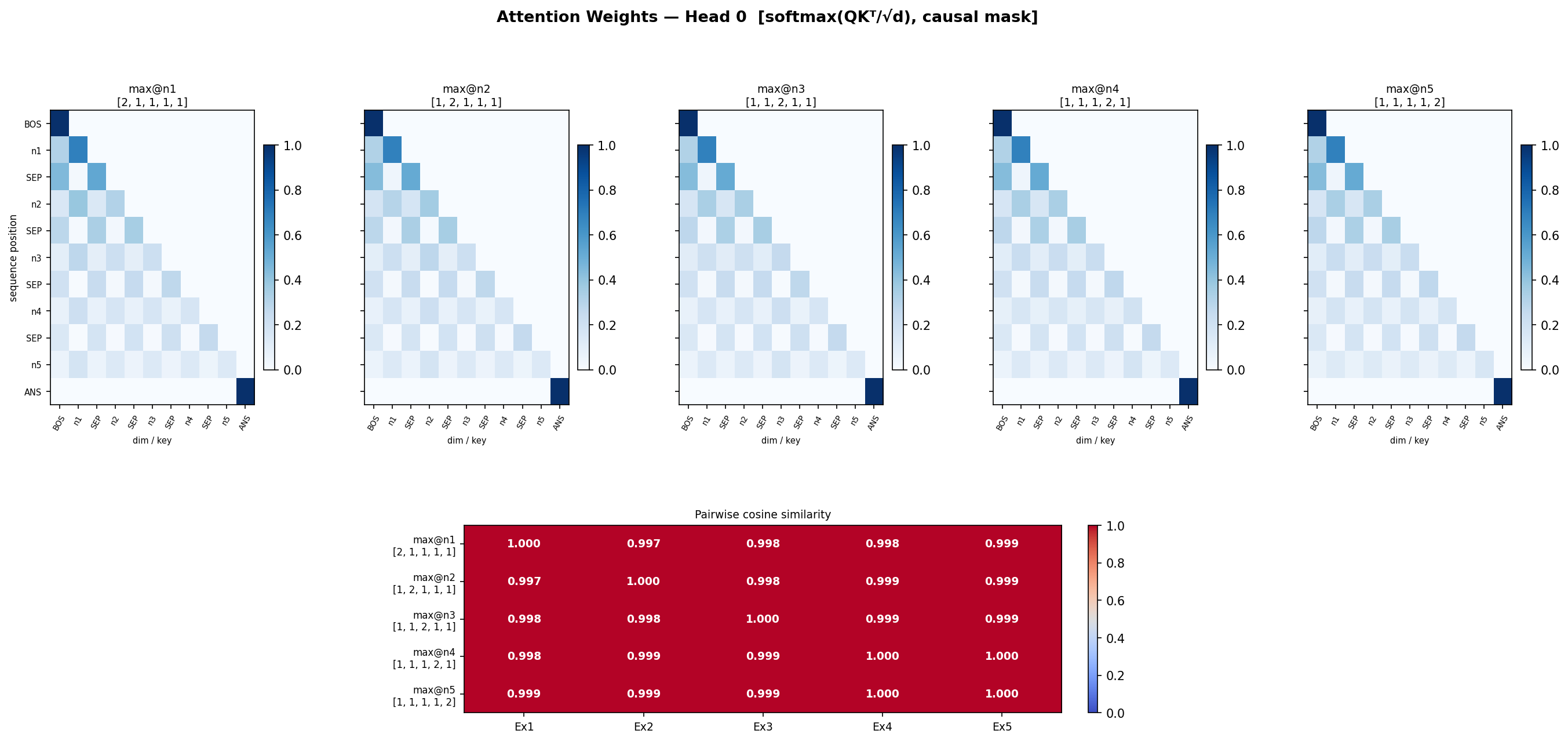
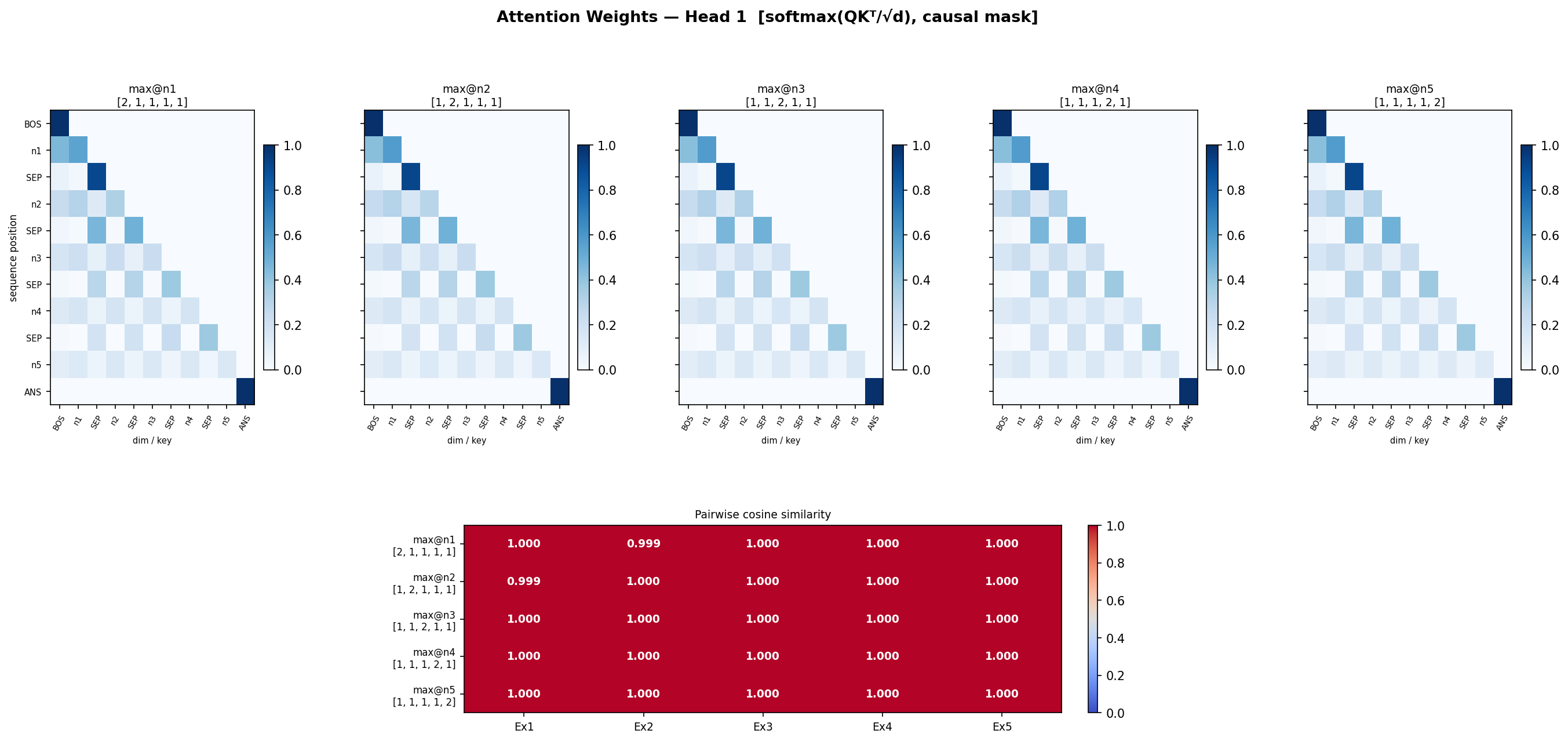
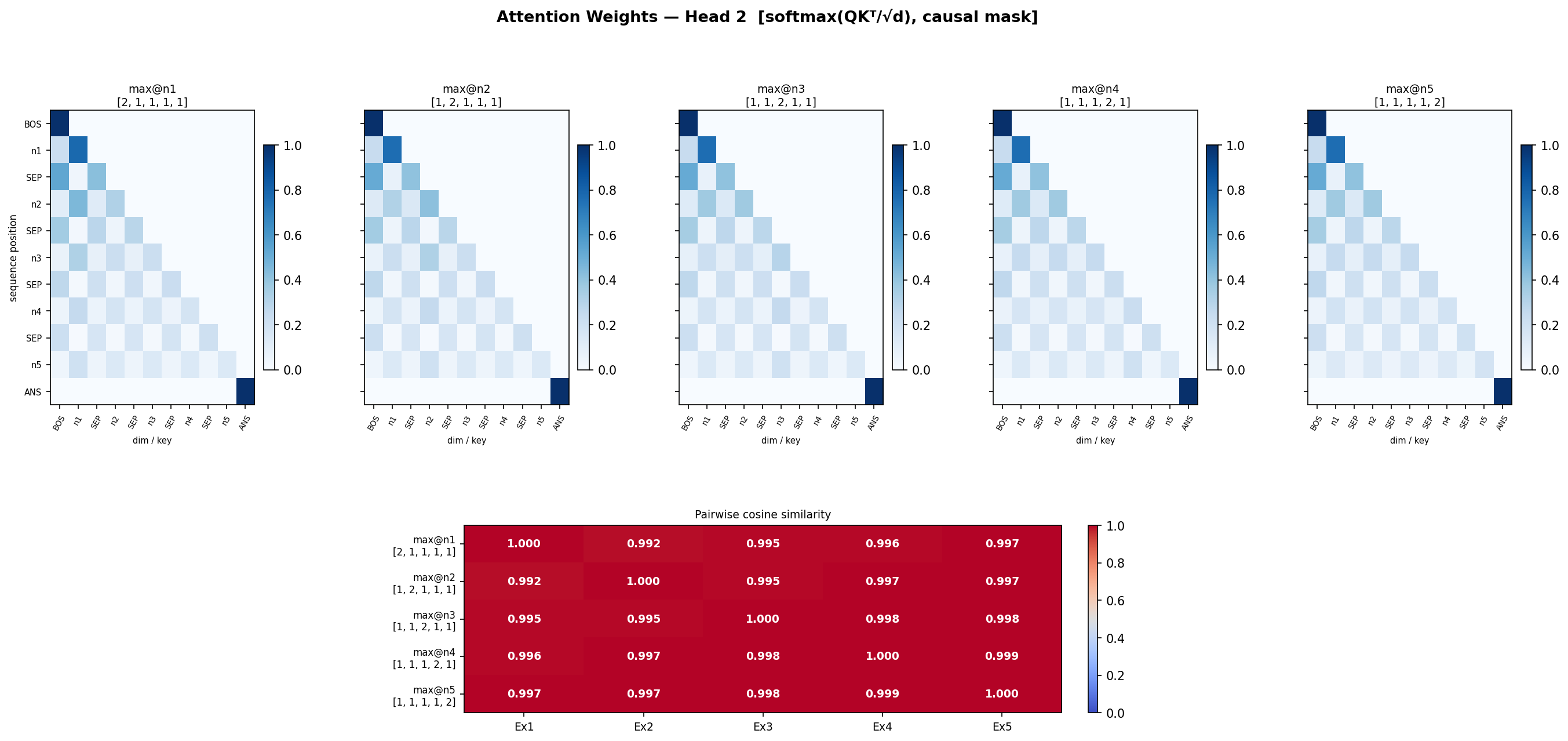
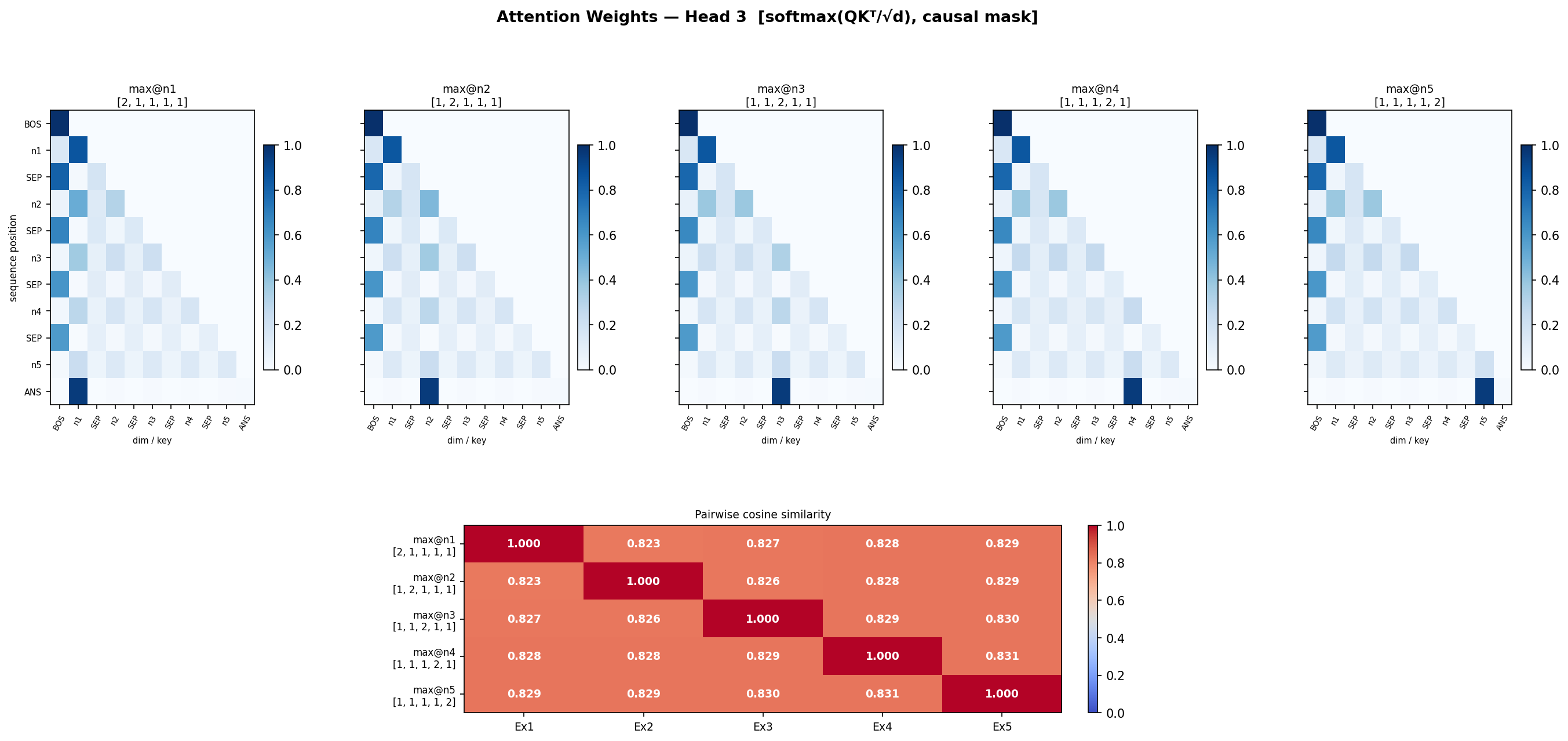
Head 3 differs the most, may be it is doing most of the job.
so may be the values before and aftter attention might also follow the same pattern?
-
Before attention, all the value vectors were very similar btn examples (0.99)
-
but after attention , even in head 3 where attn matrices were different(0.8) similarity,
-
 from concatentation , i guess everything remains same
from concatentation , i guess everything remains same
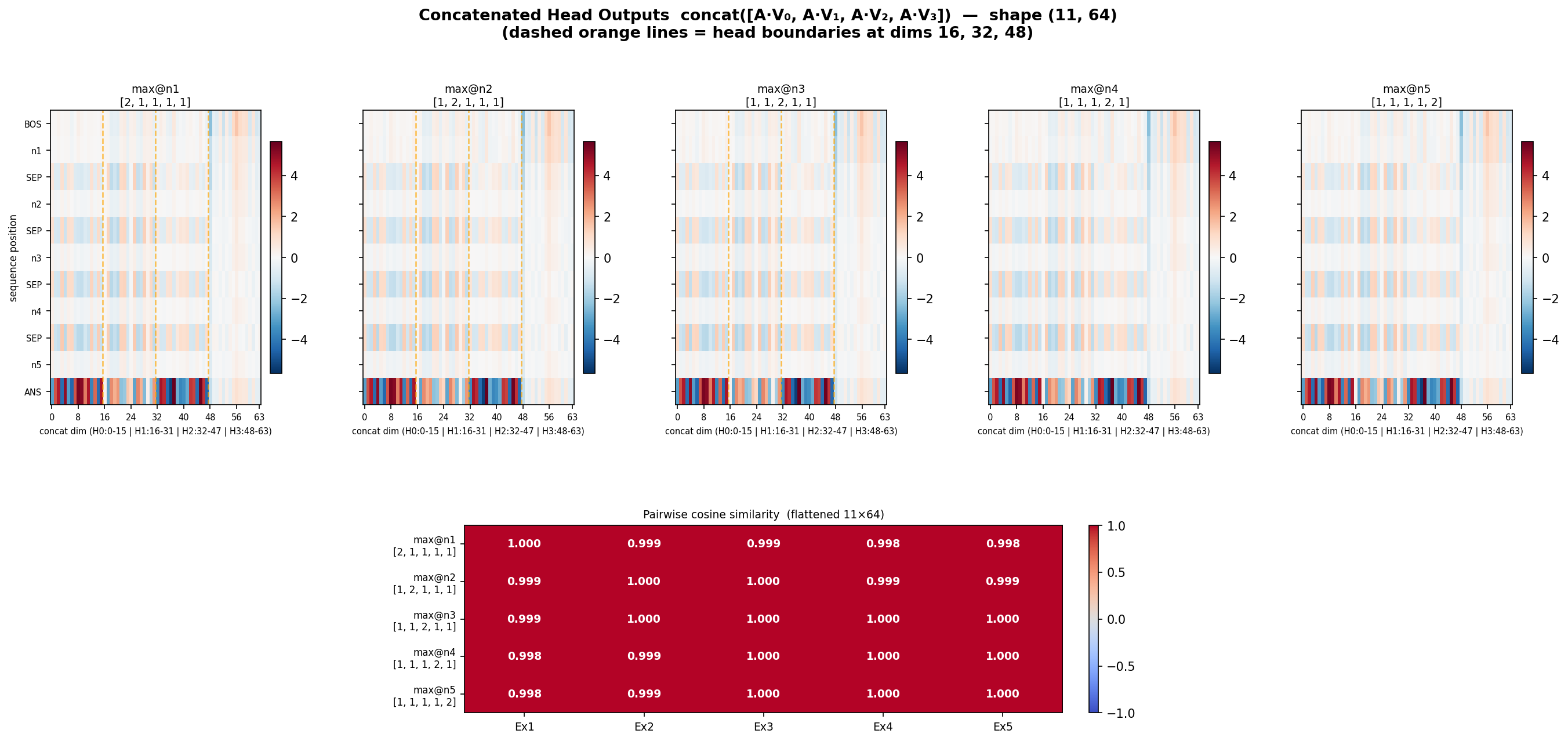 W_O x value concatenated
W_O x value concatenated
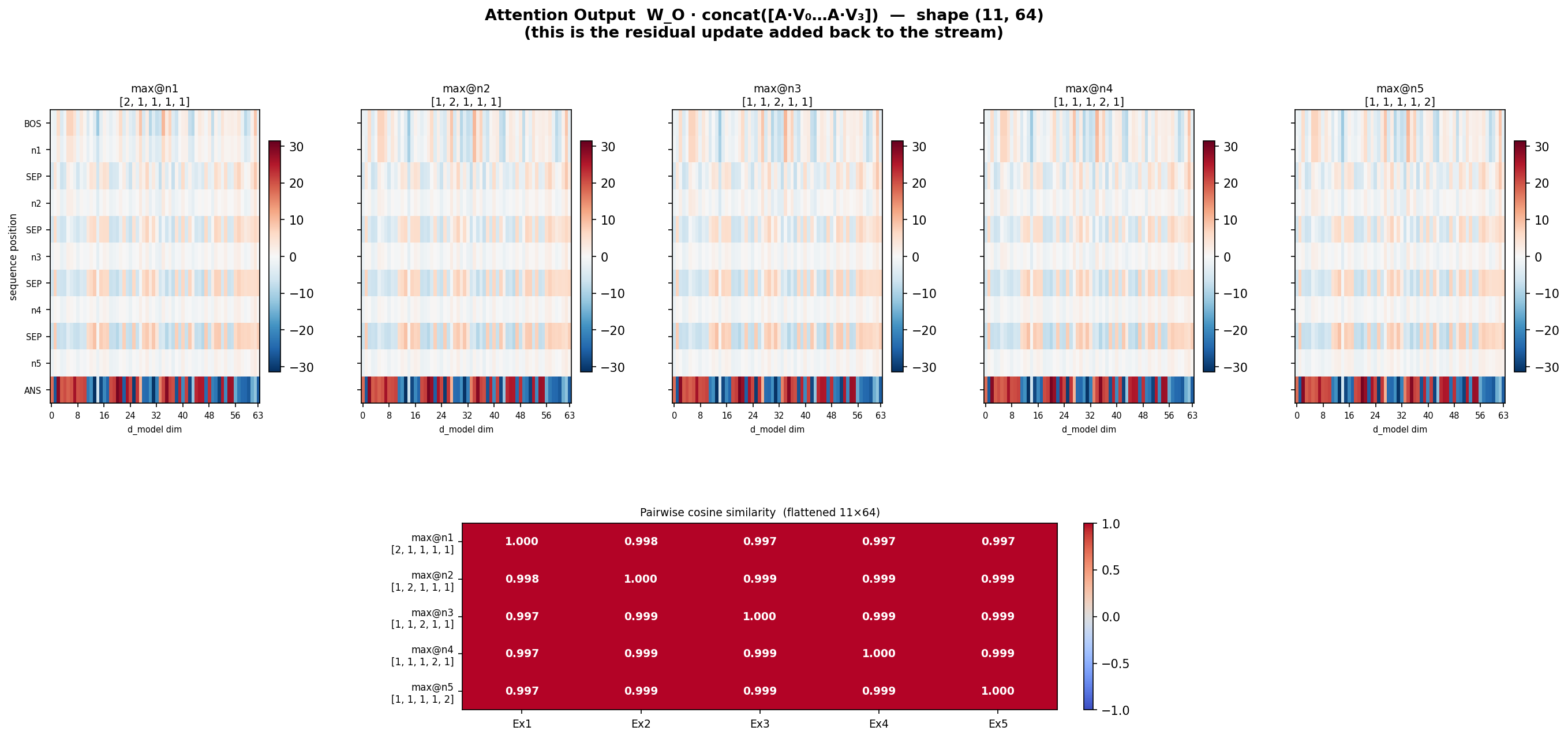
-
thought it seems like head 3 is doing most of the job, u require them together
-
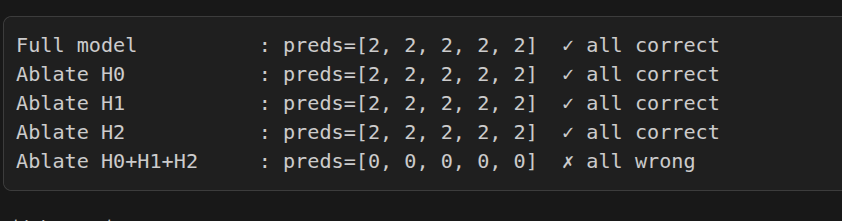
-
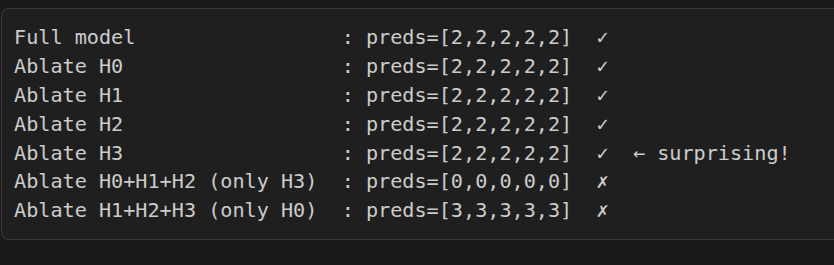
-
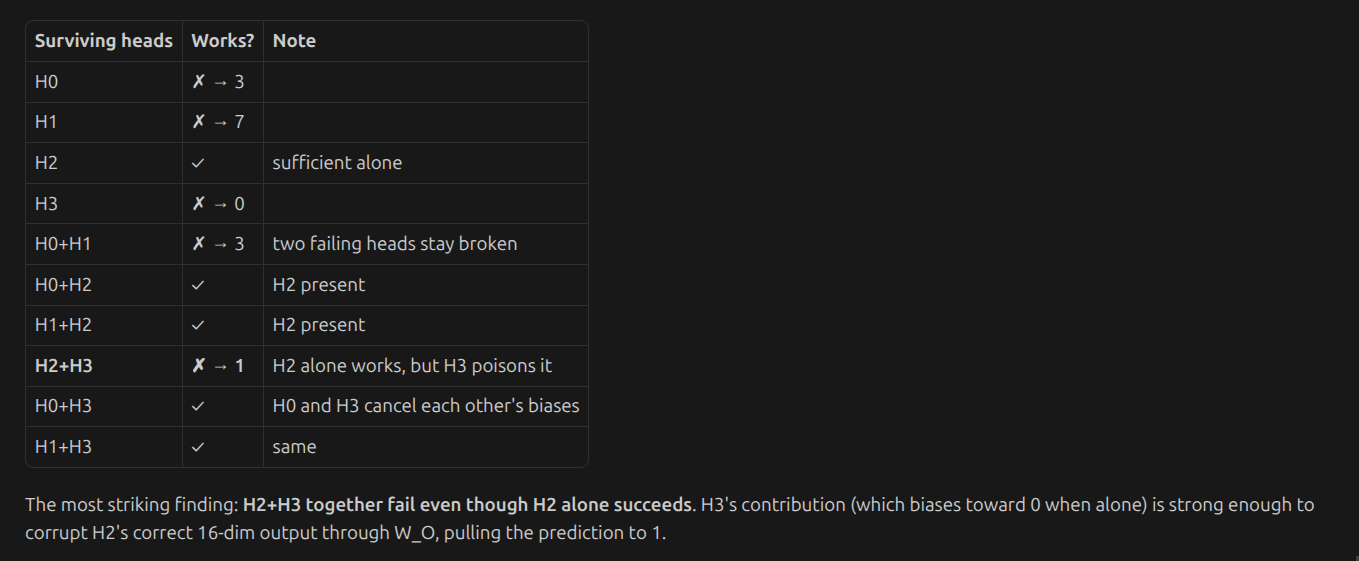
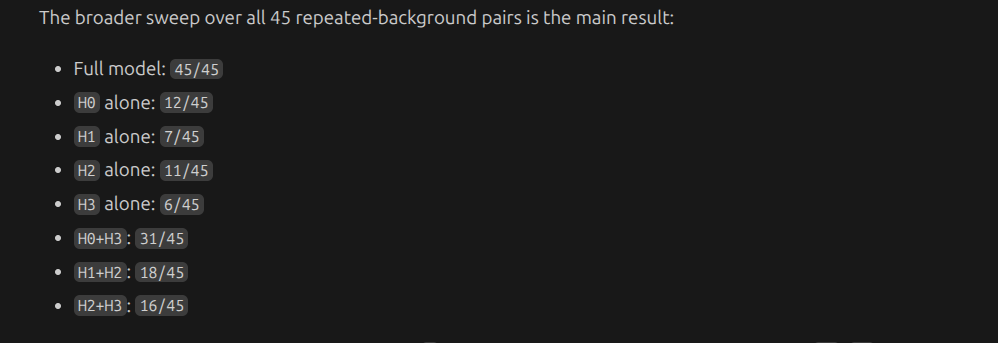
it seems model can survive any of the fall and pair wise ablation
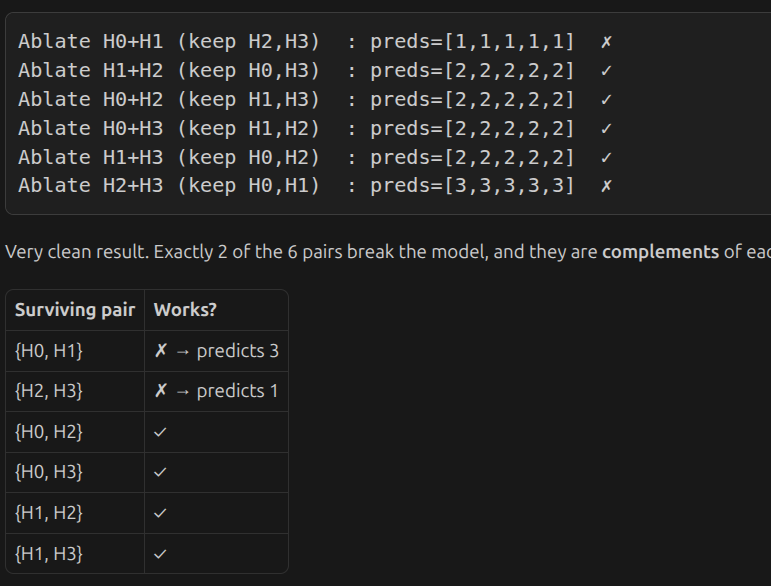 one interpretation:
The heads split into two functional groups: {H0, H1} and {H2, H3}. You need at least one head from each group for W_O to produce the correct answer. Any cross-group pair of 2 heads is sufficient; any within-group pair of 2 heads is not.
one interpretation:
The heads split into two functional groups: {H0, H1} and {H2, H3}. You need at least one head from each group for W_O to produce the correct answer. Any cross-group pair of 2 heads is sufficient; any within-group pair of 2 heads is not.
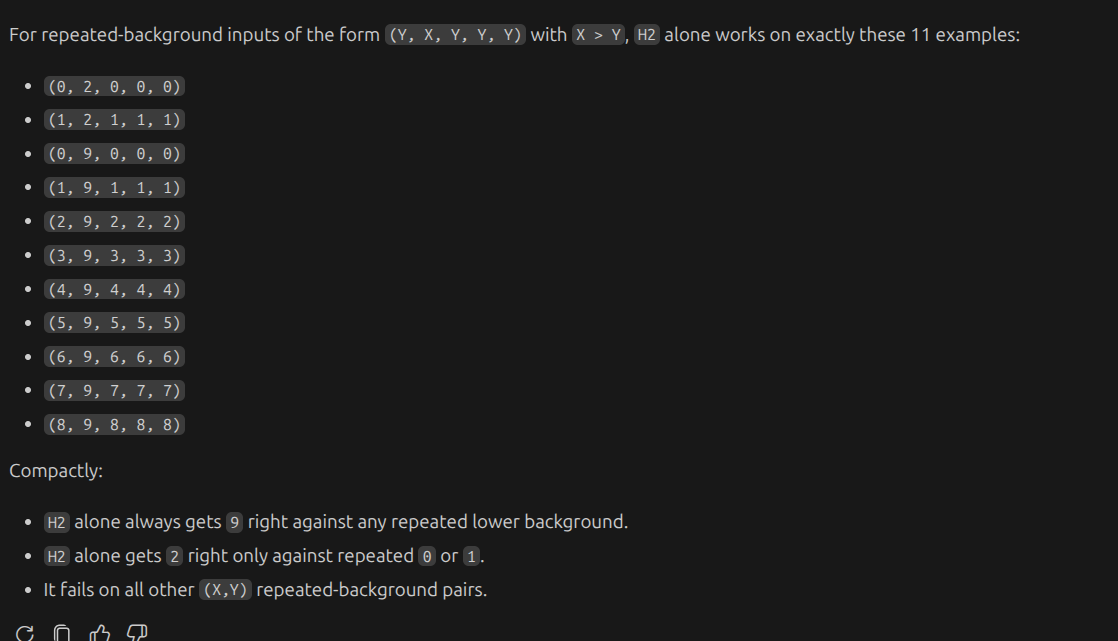
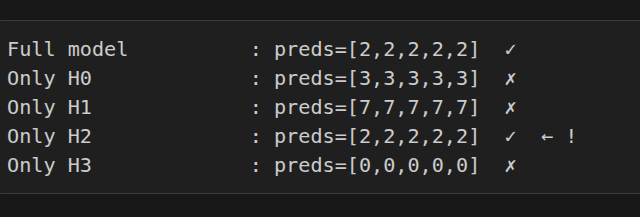 interestingly, H2 on its on can predict correctly
interestingly, H2 on its on can predict correctly
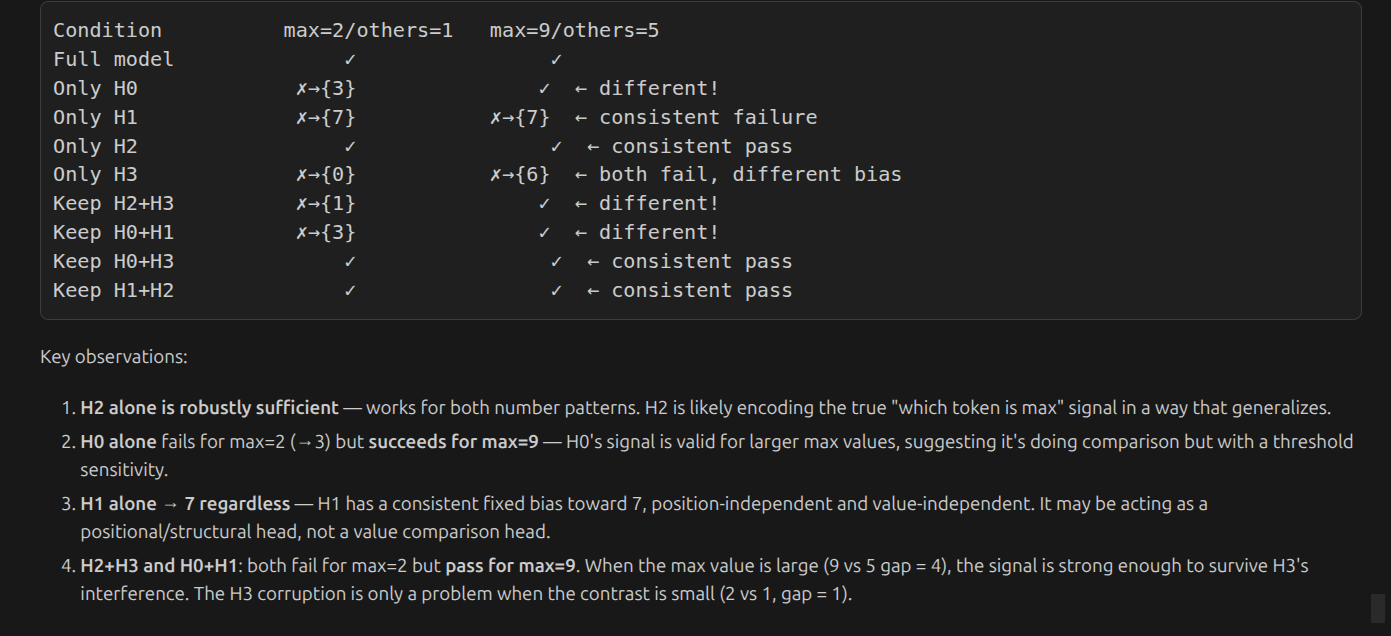
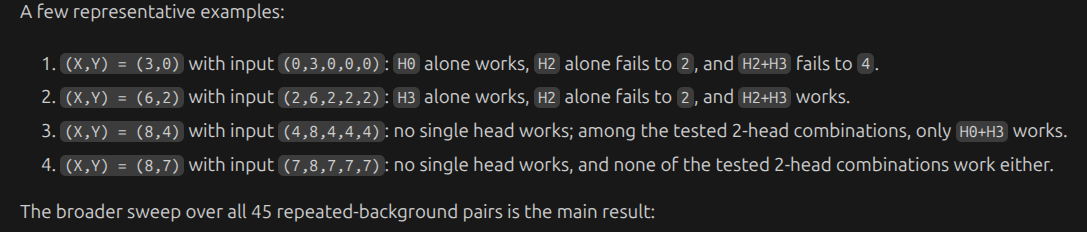
h2 alone works on thse cases
Direct logit contribution
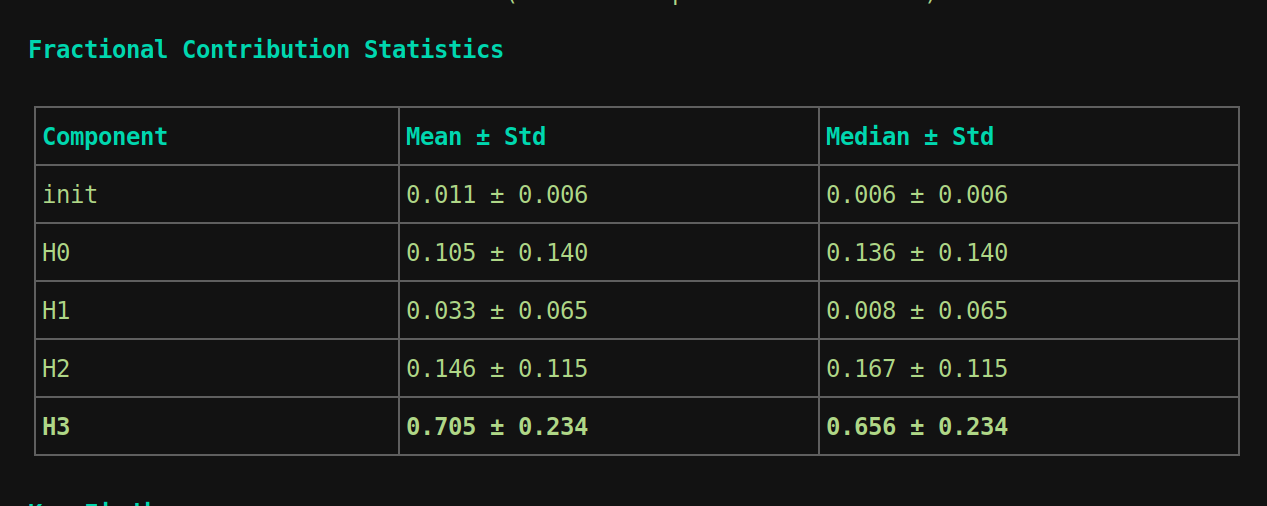 logit = init residual stream * W_U + attention output * W_U,
so u can calculate contribution of each part of the network. Head 1 as expected has around 0.8 %, little as expected. H3 is 65 %. and also init residual stream is around 6%.
so H0, H1 and H3 are doing something.
logit = init residual stream * W_U + attention output * W_U,
so u can calculate contribution of each part of the network. Head 1 as expected has around 0.8 %, little as expected. H3 is 65 %. and also init residual stream is around 6%.
so H0, H1 and H3 are doing something.
Now attention to max token